LinkedIn Dwell Time is a bit like a discussion about sex between prepubescent teenagers: everybody talks about it, but nobody really knows what it is.
Nevertheless, it has become a central element in LinkedIn‘s algorithm. Let’s take a closer look. 👀 (Reading time: 2 minutes).
How does the LinkedIn algorithm work so far?
Before talking about “Dwell Time”, it’s important to talk about how the LinkedIn algorithm works. I’ve already done a detailed article on the subject, but here’s a summary.
Every day, thousands of people publish on LinkedIn. Every day, millions of posts are seen on LinkedIn. 👀
To connect the two: an algorithm that will determine who should see whose post.
Since LinkedIn gets paid on ads, and ads are displayed every 5 posts, you need to get users to scroll through as many posts as possible to generate maximum revenue. 👀
So show the most interesting posts. 👀
But since the algorithm isn’t smart enough to understand the content of a post and determine whether it’s “interesting”, it’s going to rely on users’ interactions with the post (along with other criteria like the presence of a link, video, image, etc…).
These are other criteria that can influence reach). 🎯
Until today, the interactions studied by the algorithm corresponded to engagement: the number of likes received and the number of comments published at the start of the post’s life.
Comments carry far more weight than likes.
Then came Dwell Time…
What is LinkedIn Dwell Time?
Dwell Time represents the time you spend viewing a publication on LinkedIn, without necessarily interacting (liking, commenting or sharing). It is divided into two phases:
- 1️⃣ Before clicking on “See more” ⭢ time spent reading the visible part of the publication.
- 2️⃣ After clicking on “See more” ⭢ time spent reading the entire publication.
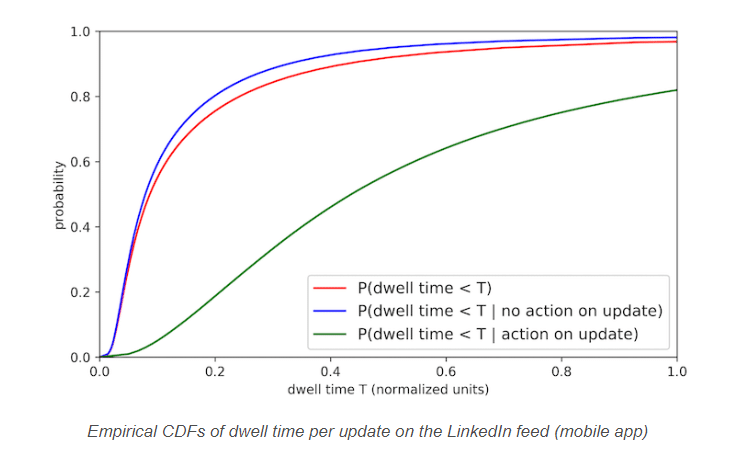
LinkedIn uses this data to assess the relevance of a publication and adjust its reach accordingly.
Why is Dwell Time so important?
There are two main reasons for Dwell Time. The first is the most important, and is the official version.
The second is secondary and unofficial.
On a social network, the following breakdown is observed:
- 1% of users publish.
- 10% of users engage (like or comment).
- 90% of users consume content without interacting.
So LinkedIn asked itself: how can we take into account the opinion of the 90% who don’t interact? 🧐 How can we ensure that the behavior of the 90% can help us determine the quality of a post?
On the other hand, engagement actions are binary. This poses two problems:
- They are not linear. 1 like is worth 1 like, 1 comment is worth 1 comment. Yet I’ll put the same like on content that made me smile or on the best post I’ve ever read. ☝️
- They’re easy to fake: just ask people I know to put likes or comments or use pods to artificially boost the reach of my content.
In fact, it’s this second point that corresponds to the second unofficial reason: to limit the impact of pods.
Measuring the quality of a post and therefore defining its organic reach by what LinkedIn engineers call “viral actions” is therefore too crude an approximation.
They also explain that clicks on a link or on “see more” in a post can be misleading indicators, as the user may immediately leave the page open or not read the rest of the post.
Similarly, indicators such as shares are not very reliable as it is impossible to objectively analyze the comment associated with the share.
Is it a share to denounce someone or to highlight quality content?

How to optimize the Dwell Time of your publications?
It’s important to understand that LinkedIn doesn’t think in terms of “is this post worth seeing?”
But “what is the most relevant post to display to this user?”
So, the algorithm will integrate various criteria, such as the user’s profile, the virality of the post (number of likes and, comments), the user’s affinity with the author of the post and other indicators such as the time of day.
By combining these criteria, it will determine the probability that you will read a post “X” and then prioritize the posts that have the highest probability of making you stop to read them.
But here are our 6 tips for optimizing your Dwell Time! ⬇️
1) Create optimized titles
The title is the first impression you give to your audience.
A good title should be :
- Clear: avoid jargon and be direct.
- Relevant: address a specific need or question of your audience.
- Intriguing: arouse curiosity, but not too much.
For example, instead of “Improve your LinkedIn profile”, put “5 steps to turn your LinkedIn profile into a recruiter magnet” instead.
2) Write for humans
Your content should speak to your audience, not to the algorithms. To do this, adopt a conversational tone and, above all, use anecdotes!
Also, don’t hesitate to ask open-ended questions to encourage interaction. 🫱🏽🫲🏼
For example, you could say: “Have you ever felt that your LinkedIn profile doesn’t really reflect who you are? Here’s how to remedy that.”

3) Bring context to every post
Each publication must stand on its own and be understandable without external context.
Basically, explain: 👇🏼
- Why the topic is relevant.
- Share data or personal experience.
- Conclude with a clear lesson or recommendation.
If you share a telecommuting statistic, accompany it with a reflection on its impact in your industry.

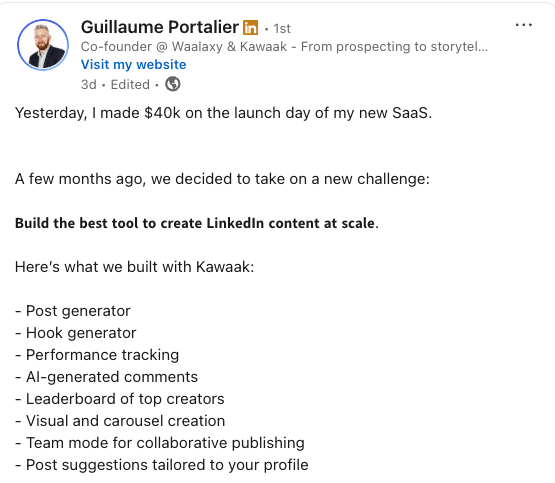
4) Engage with a visual
We’re the first to fall for it: visuals attract attention.
For this, you can use :
- Images.
- Infographics.
- Carousels.
Make sure your visuals are high-quality, relevant and, above all, consistent with your personal brand.

For example, a carousel showing the different stages of a process can make users want to spend more time on your publications.
5) Structure your publication
A good structure makes it easier to read and holds attention. So use :
- Short paragraphs.
- Bulleted lists.
- Subtitles.
This allows readers to quickly scan the information and become more engaged.
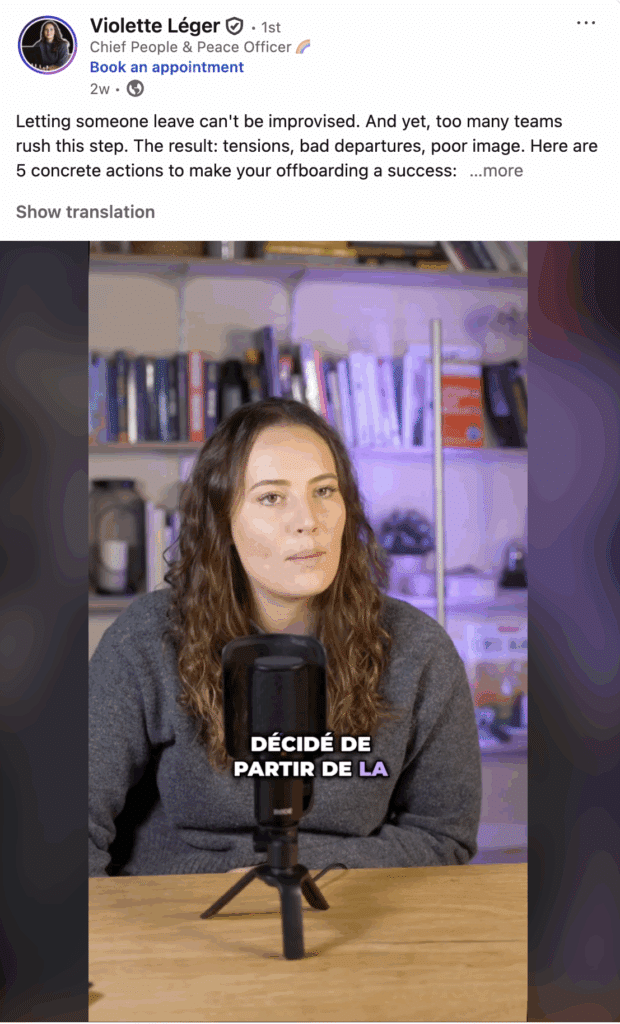
6) Use video
Last but not least, use video. Video is a format that captures and holds attention quickly.
On LinkedIn, native videos (uploaded directly to LinkedIn) are favored by the algorithm.
Therefore, make sure your videos are short (between 30 and 90 seconds), subtitled, and deliver clear value from the very first seconds. ⏱️
How about a recap?
This algorithm update is said to have significantly increased the quality of the News Feed by reducing the number of “past” posts, and therefore increased the relevance of the content on offer. 💭
The workings of the algorithm and the exact integration of Dwell Time into the reach of publications are not fully disclosed. The modeling incorporates complex mathematical functions and machine learning.
So it’s far more complex than something binary. 🌌
The engineering team does hint that updates will be made to this algorithm on an ongoing basis, so as to improve suggestions and make it ever more relevant.
In the face of these evolutions, the key to success remains content quality.
The more the algorithm can understand how much users appreciate a piece of content, the more the quality of that content will take precedence in the algorithm.
In short, Dwell Time is a bit like a date: if the conversation is interesting, you stay longer.
Well, on LinkedIn, it’s the same thing! Your content needs to captivate, retain and make people want to stay.
So ask yourself: is your publication worth our attention? 👀
Frequently asked questions
What does Dwell Time mean on LinkedIn?
Dwell Time on LinkedIn measures the time a user spends viewing a publication, without necessarily interacting.
It reflects the real interest aroused by the content and influences its reach in the News Feed. 🧲
What’s the right average Dwell Time on LinkedIn Ads?
The average Dwell Time varies depending on the ad format:
- Ads in News Feed: approx. 2.68 seconds.
- Ads on the network: approx. 17.5 seconds.
- Ads on connected TV: approx. 23.55 seconds.
- These figures serve as a benchmark for evaluating user engagement with your ads.
What is Dwell Time in SEO?
In SEO, Dwell Time is the time a user spends on a page after clicking on a link in the search results, before returning to the results. 📄
A high Dwell Time generally indicates that the content is relevant and meets the user’s expectations, which can indirectly improve the page’s engine ranking.
How is Dwell Time Calculated?
LinkedIn does not provide direct access to Dwell Time metrics for organic posts. However, you can estimate it by monitoring the following indicators:
- “See More” Clicks: A higher number suggests that users are interested in reading beyond the initial preview.
- Video View Duration: For video content, longer average watch times indicate greater engagement.
- Engagement Metrics: Analyzing likes, comments, and shares can offer insights into how compelling your content is.
For a more detailed analysis, consider using third-party analytics tools like Shield Analytics or Hootsuite, which can provide deeper insights into user interactions and content performance.
Now you know all about Dwell Time ! ⌛️